
Almost all higher trim vehicles from 2016 offer a feature called "Forward Collision Warning". Many vehicles can even detect a pedestrian and a vehicle in front of the driving car. Within the next few years, we will witness the first self-driving cars on the road. Currently, vision algorithms are being tested at Google and Tesla that give self-driving cars optimal performance.
In this article, I will demonstrate how 'Artificial Neural Network' can be used to implement a part of 'Forward Collision Warning' feature in a smart vehicle. I will create a very simple model of Artificial Neural Network that can detect a vehicle and a pedestrian. Just for the sake of simplicity, this model wont detect the closing distance (with speed) of the front vehicle, rather it will simply detect if the object is either vehicle or pedestrian. Before that, I will try to introduce the basic concepts of artificial neural networks.
We assume that a camera is installed in the front of the vehicle that captures the image of an object. A special program will analyze the image and detect the height and width of the object, and use the information to identify the image as a pedestrian or vehicle. Okay, you may argue that, if the height and width of the object is already detected by that 'special program' then the job is already half done. Yes, detecting the height and width is also part of the task of an artificial neural network. But, for simplicity, lets assume that we have already got that data. And based on that data, we perform higher level detection. Once you have clear idea about how to perform that higher level detection, you will be able to implement neural network for performing lower level detection like 'height', width' etc.
Ok, lets get back to the original problem. We captured the image of an object from the front camera of the driving car and we received the width and height data of the object. Also our 'special program' provided the percentage of light reflected from that object.

In most cases, the width / height ratio of a car is higher than the width / height ratio of a person. Right?
If we collect the width/height of various vehicles and pedestrians, we will begin to notice a pattern. Usually, the width / height ratio of a human is smaller than the width / height ratio of a vehicle. We also notice that there is a pattern in the percentage of reflected light from a vehicle and a pedestrian. Unless a pedestrian wears a shiny, reflective dress, the pedestrian’s clothes absorbs more light than a vehicle’s exterior. So, there is a pattern that begins to emerge between the reflected light percentages of a vehicle versus the reflected light percentage of a pedestrian.
The intent of this article is to explain how an intelligent system like artificial neural network can be used to identify vehicles and pedestrian by recognizing patterns. Obviously, recognizing patterns just by width/height ratio and reflected light percentage won’t be sufficient in real world. This algorithm is just for providing you an illustration about Pattern Recognition by Artificial Intelligence. So for the sake of simplicity, we are assuming that width/height and reflected light percentage would be sufficient.
Pattern Recognition
Patterns are everywhere. When we were kids, we learned new objects all the time by identifying shapes. At the beginning, when our parents showed us a tennis ball and a football, our brain stored those 2 types of balls in our memory. Then when we saw a basketball, our brain matched the new shape with the various items in our memory and found that the new shape (basketball) closely matched the tennis ball and the football. So, we assumed that the new object must be a ball. It wasn’t a pen or a cup. It was a ball. When we saw another type of ball, (say volleyball), we could tell that it must be a ball too. So, the more data we gathered, the more efficiently we recognized the pattern of objects. In this same way, we learned to detect new kind of pencils, pens, toys, etc. We saw hundreds of pens and pencils throughout childhood, and therefore, it takes less than a second for our brains to tell if a new object is a pen or pencil because the new object closely matches the pattern of previously seen pens and pencils.

Our brain can efficiently recognize new objects by finding the similarity / pattern of previously seen objects, and that is what we call pattern recognition.
We will use Artificial Neural Network to recognize patterns for solving a problem in the same way that the human brain can recognize a pattern.
What is an Artificial Neural network?
In brief, our brain is composed of nerve cells or neurons. It is not necessary to dwell herein any further on the biology of neural network.
An artificial neural network is actually a mathematical function that can take input information and process it and output the processed information. What do I mean by processing here ? Here, I mean, detection. The function can take a data and tell if the data falls into any specific category or not. So, for example, a function can be used to process an image of an object and provide the width or height of an object. Another function can take that processed information (width or height) and detect if the object is either vehicle or a pedestrian.
So, one layer of functions are used to detect height, width, reflected light percentage etc, and another layer of functions can be used to process those height / width information to perform the final detection. Such inter-connected artificial neurons are called an artificial neural network.
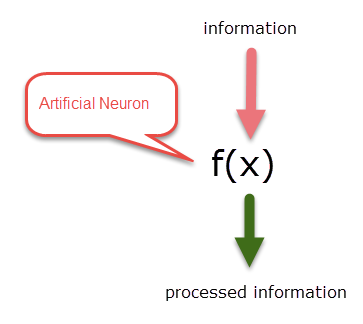
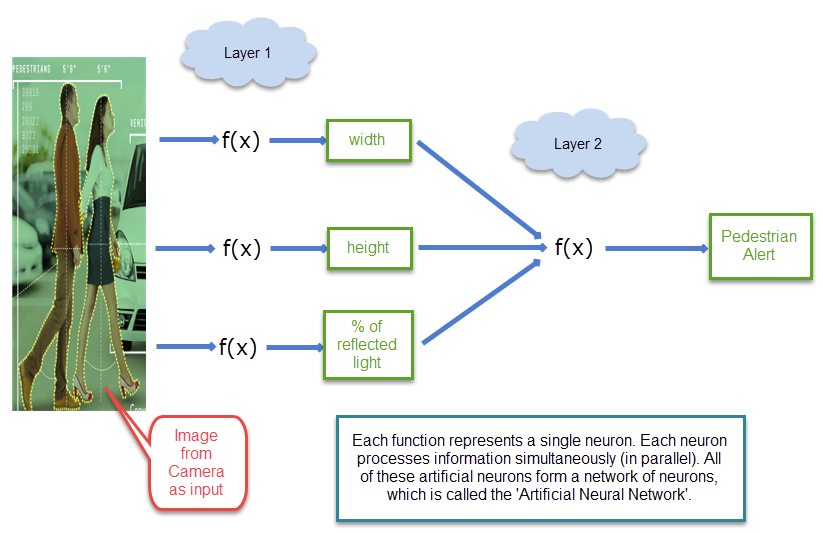
An artificial neuron is a conceptual model of a biological neuron implemented by a mathematical function that can process information. Similar to a biological neural network, an artificial neuron can be interconnected to solve complex problems. One neuron can process one piece of information and that processed information can be passed to another layer of neurons to do more processing; Each neuron in an artificial neural network performs a pattern detection.
Why use an Artificial Neural Network?
A computer can instantly search for a specific word in a large MS Word document, but it is very difficult for a human brain to do so quickly. At the same time, there are various problems that our brain can solve easily which is difficult for traditional computing to do. For example, the human brain can see the handwritten letter ‘A’ written by anyone and recognize that letter as the letter ‘A’ in a split second, something that is difficult to do with traditional computing Every person writes the letter ‘A’ differently. Not only that, the same person can write the letter ‘A’ differently at different times. So, there are almost hundreds, (if not thousands or millions), of ways to write the same letter ‘A’. Of course it is not practical to store those hundreds or thousands or even millions of images of the letter ‘A’ in a database and compare the handwritten ‘A’ to each one. Here comes the power of Artificial Neural Network. An artificial neural network is a conceptual model of our brain’s neural network. To detect a handwritten letter as efficiently as the human brain; an artificial neural network can be trained to recognize various handwritten letters.With more training, the artificial neural network becomes more efficient in recognizing various types of handwriting. This type of computing model is extremely capable of resolving problems in situations where preliminary information to solve the problem is not known in advance. Therefore, we can train an artificial neural network with various sets of vehicles and humans comparing width/height ratio and percentage of reflected light. Over time, our artificial neural network will be smart enough to identify an object as either a vehicle or a pedestrian. To explore this process, let’s consider the different ways an artificial neural network can be trained.
Supervised Learning
Remember the handwritten recognition example. If we want an artificial neural network to recognize specific handwriting, it must be trained with various handwritten letters, such as A, B, C, D, etc. In the beginning, the network has no idea what comprises a letter. So, it considers the letter ‘A’ to be any random letter. Once it considers the handwritten letter ‘A’ as any letter other than ‘A’, the network is instructed that, "WRONG. The demonstrated letter is ‘A’”. Then, the network determines the difference between ‘A’ and its wrongly perceived letter. This difference is called an ‘Error’. Based on this error, it adjusts the various parameters within its network so that the next time the error occurs it’s minimized. In this same way, it can continue calculating errors, and adjusting parameters when presented with other handwritten letters. Over time, the more samples the network is presented with;, the less errors the network produces. Its parameters for recognizing handwritten letters are more fine-tuned and matured. This process is called Supervised Training. In our example problem (detecting a vehicle versus a pedestrian, we will use supervised training).

Unsupervised Learning
Obviously, supervised training is simpler, but it is not always a practical way of learning. Let’s find out why. Let’s say for example, you invented a robot and sent it to an unknown planet. The robot’s mission is to learn about the planet’s environment on its own. We do not have the luxury of knowing the planet’s environment and geology, or the time to train the robot before sending it to the unknown planet. But we do want the robot to teach itself to avoid dangerous environmental situations. So, at this point, let’s consider using unsupervised learning as a way to train the robot. Unsupervised learning is a way of learning by finding patterns among unknown objects, and labeling those patterns with its own naming criteria.

Say for example, the robot sent to the new planet was not taught about color. So, when the robot encountered RED colored soil, it stored that color information in its memory and labeled the color with some random word ’COLOR-A’. The next time it finds a similar colored soil, it knows that the color of that soil is COLOR-A.
When the robot finds green grass on the planet, it knows that the GREEN color must not be the same color as COLOR-A. It is a new kind of color, and it labels the color as ‘COLOR-B’. So, whenever the robot finds a new color field, which is either RED or GREEN, the robot classifies that color field as either COLOR-A or COLOR-B. In that way, the robot can learn about the many colors of the planet. Not only that, once the robot encounters a Pink Color or some slightly less bright red color, it knows that the color must not be COLOR-B, so it must be somewhat closer to COLOR-A. So, we see that unsupervised learning is a smarter way of learning than supervised learning. For simplicity, we will stick to only supervised learning in this article.
Reinforcement Learning
Reinforcement Learning is another type of learning. . An example can be given with the same robot on the unknown planet. If the robot finds that the RED colored soil is dangerous because the soil contains ACID which damages the robot’s body, the next time the robot encounters a reddish soil (COLOR-A), it will avoid that soil.
Meet the Perceptron
To identify patterns in our example of detecting a vehicle and pedestrian on the road, we will use Perceptron, a type of neural network. Perceptron is the most rudimentary neural network found. Invented by Frank Rosenblatt at the Cornell Aeronautical Laboratory in 1957, it is a computational model of a single neuron. A perceptron is simply one or more inputs, a processor and one output.
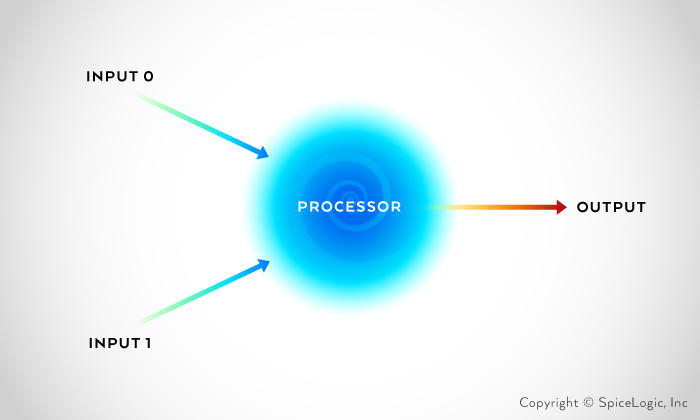
A perceptron adheres to a ‘feed-forward’ model. This model means that an input(s) are delegated to the neuron and processed, which then results in an output. In the schematic above, the one neuron (network) interprets the input from left to right meaning input(s) come in and an output comes out.
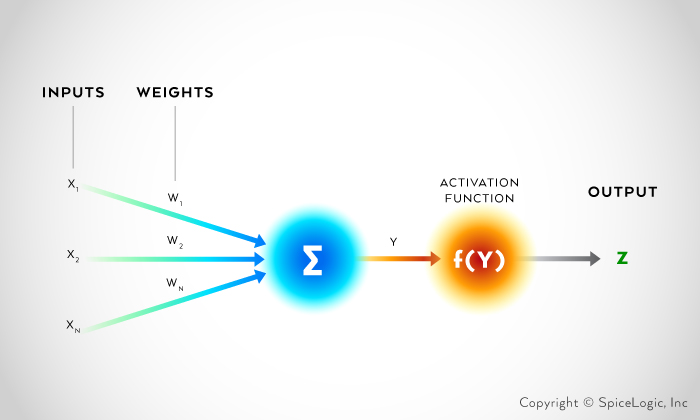
Detecting a pattern using Perceptron is a procedure of multiplying inputs with some weights, and then summing all weighted inputs. After summing all weighted inputs, a bias can be added. Once the weighted sum is calculated, the result is passed to another function named Activation Function which finally determines and classifies the pattern.
This procedure can be expressed with following equation:
Y = Σ (W * X) + b
Detection Result = f(Y) = Activation Function
Y represents the sum of all weighted inputs. W is weight and X is the input. ‘b’ is the Bias.
What is Weight?
Let’s learn by example. Here is a set of scores about some students in a class as follows:
Student Name | Academic Performance | Cultural Performance |
Mike | 23% | 36% |
Jason | 32% | 20% |
Paul | 23% | 28% |
First, let’s classify these students into 2 groups. The groups will be good students and bad students. To determine if a student is good or bad, this data must be processed to create a pointer number.
Let’s consider 60% weight on cultural performance and 40% weight on academic performance. To sum the performance value according to weight, we must determine if the value is greater than 25. If the value is greater than 25, then the student is a good student; otherwise, the student is a bad student. Our student evaluation algorithm can be shown using a diagram as follows:
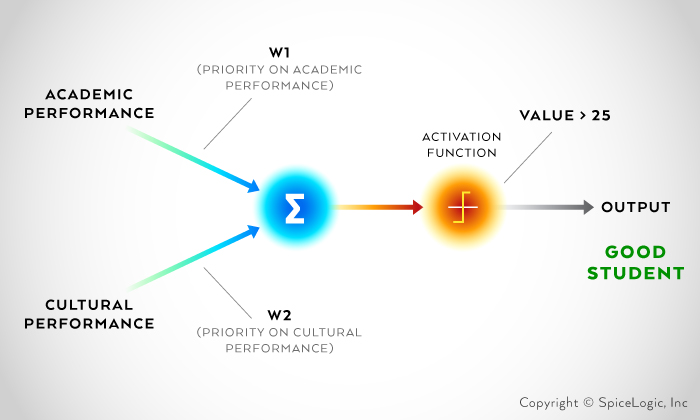
According to the mentioned criteria, let’s calculate the value of the students:
Mike = 0.4 * 23 + 0.6 * 36 = 30.8
Jason = 0.4 * 32 + 0.6 * 20 = 24.8
Paul = 0.4 * 23 + 0.6 * 28 = 26
Jason’s value is 24.8 and is not greater than 25. So, Jason is classified as a bad student. Mike and Paul are good students because their values are greater than 25.
Now, let’s evaluate the students according to academic performance. Let’s consider 70% weight on academic performance and 30% weight on cultural performance. Based on this new decision, let’s recalculate each student’s value as:
Mike = 0.7 * 23 + 0.3 * 36 = 26.9
Jason = 0.7*32 + 0.3 * 20 = 28.4
Paul = 0.7 * 23 + 0.3 * 28 = 24.5
Now, Paul’s value is less than 25, so Paul is a bad student. Mike and Jason are good students because their values are greater than 25. In this scenario, it is weight that classifies the data. It is also weight that is used to recognize patterns from the sample data. When supervised training was explained, I mentioned ‘parameter’ adjustment. In this example, it is the weight which is the parameter.
Both of the evaluations are based on 2 different weights, and can be visualized by the following chart.
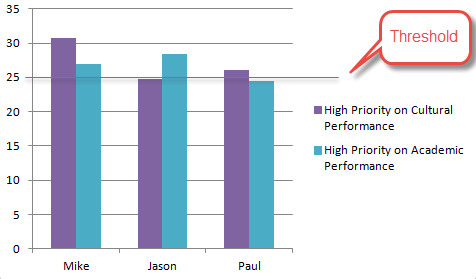
Threshold / Activation Function
In the previous example of evaluating students, the number 25 is used as a critical pass point. Here, 25 is the threshold. Checking if the weighted sum is greater or less than 25 is a responsibility of a function called ‘Activation Function’.
Bias in Details
The real world is full of bias. Examples of bias are everywhere. As I have mentioned earlier, many real world problems are very hard to solve in deterministic way. There are many variables that affect an experiment result. So, we use bias to align the result according to our expectations.
Let’s use a cooking recipe as an example. Say, you are very fond of salt. So, the recipe for cooking a meal you downloaded from the Internet is not producing the expected taste you like. So, you add some salt to every meal that you cook following the recipes you collected from the same source. That’s an example of bias in real life.
Let’s consider another example. Say you built a digital thermometer to measure temperature. You used another store-bought thermometer to verify if your handmade thermometer is showing the correct temperature. You found that whenever your thermometer shows 10 degrees C, the store-bought thermometer shows 11.5 degrees C., and whenever your handmade thermometer shows 11 degrees C, the other one shows 12.5 degrees C. So, there must be something wrong with your thermometer, but the root cause can be any number of physical properties belonging to your thermometer which is impractical to find out. Rather, if you add 1.5 degrees to all measurements, then there is an exact match of your thermometer reading to the reading from the store-bought thermometer. This 1.5 degrees C is a bias value that you add to your final measurement.
When using Artificial Neural Networks for pattern recognition, there will be lots of situations where you will get a consistent amount of positive or negative deviations from the expected result. Once a consistent amount of deviation is found, you can add or deduct that amount to fine tune your result. Therefore, bias is a calibration constant that is applicable to a network to produce a more correct result.
Training by Delta Rule
Delta rule is all about learning from mistakes.

"Failure is instructive. The person who really thinks learns quite as much from his failures as from his successes.”
― John Dewey
The concept of delta rule is really very simple to understand. We already know that the Perceptron uses weights to calculate a final value for pattern detections. Delta rule is a way of training a perceptron so that the weights are continuously adjusted to produce correct detection results. And that adjustment is done by calculating the mistakes the perceptron has done while detecting an object.
The difference between the perceptron's output and the expected output is multiplied by the perceptron’s input and then multiplied by a small learning rate. Say we have N number of data set, which we will have to calculate and update Weight change for N data. If we denote iteration as ‘i’ then, Weight i for Input i is calculated as follows:
Change in Weight i = Learning Rate × Current Value of Input i × (Expected Output - Current Output)
The above procedure can be expressed as:
ΔWi = η * Xi * E
Where η is the learning rate, E is the Error (difference between expected output and calculated output).
The new weight is equal to the previous weight plus change in weight.
Wi = Wi + ΔWi
Learning Rate Distilled
The learning rate is a parameter of an artificial neural network that determines how much change needs to be applied to a given weight based on its errors. It also determines how strongly the network learns from those errors.
Here’s another example about how the learning rate applies to driving a car. Let’s say, you are trying hard to keep your car on the road but your car is drifting too far to the right or too far to the left. When your car drifts to the right, you steer your steering wheel to the left. But the car is now moving too far to the left. So, you steer your steering wheel to the right, and this time your car moves too far to the right.
Since there must be a better rate at which you can adjust your steering based on your observation of moving right or left, let’s consider that rate as a learning rate. If you’re learning rate is too high, you will adjust your parameter for even the smallest amount of error with a strong weight, and that will cause errors from the opposite direction. You need to choose an optimum learning rate based on your situation.
Delta Rule Algorithm Explained Step by Step
Steps of Delta Rule are as follows:
1. Randomly choose the weights in the range 0 and 1.
2. Training examples are presented to perceptron one by one from the beginning, and its output is observed for each training example.
3. If the output is correct then the next training example is presented to perceptron.
4. If the output is incorrect then the weights are modified as per the following formula.
Wi = Wi + (η * Xi * E).
The value of learning rate η may be as per the following.
If output is correct then η = 0.
If output is too low then η = some positive double number in the range 0 and 0.5.
If output is too high then η = some negative double number in the range 0 and 0.5.
You may be wondering where does η =0, η = 0.5, etc. come from. Actually there is no strict rule about the value of learning rate. It is a tuning parameter that will depend on the context (problem domain), which means, we will continue to experiment and find out which learning rate works best for optimizing the weights for the specific problem. The value of learning rate should be between 0 and 1. Usually it should be a very small number, something like 0.1.
5. Repeat steps 2-4 with the modified weights.
6. Repeat steps 2-5 until all training examples have been correctly classified.
Training Started
Let’s assume that we have collected the different values of width to height ratios and the percentages of reflected light for cars and humans to train the artificial neural network. These collected values are mentioned in Table 1. Table 1: Width to height ratio and percentage of reflected light
Sr. No. | Width to height ratio | Percentage of reflected light | ||
Car | Human | Car | Human | |
1 | 1.1 | 0.1 | 0.6 | 0.1 |
2 | 1.2 | 0.2 | 0.7 | 0.15 |
3 | 1.3 | 0.3 | 0.75 | 0.15 |
4 | 1.4 | 0.4 | 0.8 | 0.2 |
Usually the width to height ratio of a car is always greater than the width to height ratio of a human. Also the percentage of reflected light from a car is usually greater than the percentage of reflected light from a human. As you see from Table 1, the range of width to height ratio is [1.1, 1.4] for cars and [0.1, 0.4] for humans, and the range of percentage of reflected light is [0.6, 0.8] for cars and [0.1, 0.2] for humans. We will use the data mentioned in Table 1 to train the artificial neural network.
Once the training has been successfully completed, we will input width to height ratios and percentages of reflected light either from the range [1.1, 1.4] and [0.6, 0.8], or from the range [0.1, 0.4] and [0.1, 0.2], and the artificial neural network will output either "Vehicle Alert” or "Pedestrian Alert”. For example, if we input the width to height ratio as the value 1.25 and the percentage of reflected light as the value 0.7, then the artificial neural network will predict it is a car and the output will be "Vehicle Alert”. While, if we input the width to height ratio as the value 0.3 and the value of the percentage of reflected light as 0.17, then the artificial neural network will predict it is a human and the output will be "Pedestrian Alert”.
Let’s apply the algorithm on our dataset for training.
At this point, we need to define an Activation Function that will determine what the weighted sum means to each object. Based on our dataset, we can think about the following activation function.

We can use different bias values to affect this threshold value.
1. We have two input variables, namely width to height ratio and percentage of reflected light. So, we will randomly generate the values of weights W1 and W2 in the range 0 and 1. Let us take W1 = 0.9 and W2 = 0.8 and bias = 0.
2. Consider the first training example for car. X1 = 1.1 and X2 = 0.6 as per Table 1. The actual output is car. Compute Z = f(Y) = f (W1*X1 + W2*X2) = f (0.9*1.1 + 0.8*0.6) = f (0.99 + 0.48) = f (1.47). Thus value of Y is 1.47>0.5. So the calculated output is also car which is correct. Therefore, it is not required to change the weights.
3. Consider the first training example for human. X1 = 0.1 and X2 = 0.1 as per Table 1. The actual output is human. Compute Z = f(Y) = f (W1*X1 + W2*X2) = f (0.9*0.1 + 0.8*0.1) = f (0.09 + 0.08) = f (0.17). Thus value of Y is 0.17<=0.5. So, the calculated output is also human which is correct. Therefore, it is not required to change the weights.
4. Similarly, we will find the correct output of the second and third training examples with the car and the human. Therefore, it is not required to change the weights for second and third training examples.
5. Let us consider the last training example for car. X1 = 1.4 and X2 = 0.8 as per Table 1. The actual output is car. Compute Z = f(Y) = f (W1*X1 + W2*X2) = f (0.9*1.4 + 0.8*0.8) = f (1.26 + 0.64) = f (1.9). Thus value of Y is 0.9>0.5. So, the calculated output is also car which is correct. Therefore, it is not required to change the weights.
6. Let us consider the last training example for human. X1 = 0.4 and X2 = 0.2 as per Table 1. The actual output is human. Compute Z = f(Y) = f (W1*X1 + W2*X2) = f (0.9*0.4 + 0.8*0.2) = f (0.36 + 0.16) = f (0.52). Thus, the value of Y is 0.52>0.5. So, the calculated output is car which is incorrect. Therefore, it is required to change the weights.
7. Here, the error produced is 1. So E = 1. Output is higher than expected, so let us generate learning rate L = some negative double number in the range 0 and 0.5. Let us take L = -0.2. Now modified weight W1 = W1 + (L*X1*E) = 0.9 + (-0.2*0.4*1) = 0.9 - 0.08 = 0.82 and W2 = W2 + (L*X2*E) = 0.8 + (-0.2*0.2*1) = 0.8 - 0.04 = 0.76.
8. Present all four training examples of car and human with these modified weights to perceptron one by one from the beginning.
9. Repeat the above steps until all training examples have been correctly classified.
Decision Boundary and Linear Separability:
Linear Separability is an important concept that needs to be discussed when dealing with Perceptron. A perceptron can be used to classify objects based on a pair of data points if those data points satisfy a special condition. Let’s review the condition using the example of identifying good students and bad students based on academic and cultural performance. With the scores of academic and cultural performance, we could multiply the scores with associated weights to get an indicator number which we would compare with a threshold value. In that way, we form a decision boundary between good students and bad students.
We could argue that for some combination of academic and cultural performance score a different threshold other than 25 would be appropriate. For example, if academic performance is extremely high (almost 100%) but cultural performance is very low (like 0%), then we may want to consider the student as a good student even though the weighted sum of the score could be below the threshold. In that case, we won’t be able to classify a student based on a single threshold number. This is an example of a Linearly Inseparable dataset.
Multi-Layer Perceptron
When we have a set of linearly inseparable data, we cannot use a single perceptron for a classification task. If the linearly inseparable dataset can be divided into many groups where the data set within the group is linearly separable, then we can use a perceptron to classify data within each group. Finally, using a complicated activation function, we can accomplish the pattern detection task.
Say for example, we have 4 objects, "Apple”, "Orange”, "Daisy” and a "Rose”. We want a neural network to identify these 4 objects. The parameters for Apple and Orange can be similar but they won’t be similar to Daisy and a Rose. Definitely, the dataset for these 4 objects would be Linearly Inseparable. So, we can divide these 4 objects into 2 groups; Group 1 – "Fruits”, and Group 2 – "Flowers”. Then we can use one perceptron to identify the objects by the group "Flower” or "Fruits”. Then within the Flower Group, we can have 1 perceptron to detect "Daisy” and "Rose”, and within the Fruits group, we can have another perceptron to detect "Apple” and "Orange”.
Backpropagation
Backpropagation is a technique used for optimizing weights of a multi-layer artificial neural network. The procedure is kind of similar to a single layer artificial neural network. When training a multi-layer artificial neural network, the calculated error, which is the difference between the final output and the desired output, is passed backward (right to left) in order to adjust the weights of all connections.
Source Code
I have prepared a C# project demonstrating the concept of Perceptron. In this project, I have created a Perceptron that can do binary classification based on data (i.e. Width to Height Ratio and Percentage of Reflected Light). The perceptron will produce a binary result. 1 for Vehicle and 0 for Pedestrian. The core method snippet is listed here for your convenience. The complete Visual Studio Solution is attached to this article too.
public class NeuralNetwork
{
/// <summary>
/// The correct expected result for vehicle. We consider our neural network as a binary classification network
/// where the network can output 2 values. 0 or 1. We program the network so that if the network output is 1,
/// then the object must be a Vehicle.
/// </summary>
private const int CorrectExpectedResultForVehicle = 1;
/// <summary>
/// The correct expected result for vehicle. We consider our neural network as a binary classification network
/// where the network can output 2 values. 0 or 1. We program the network so that if the network output is 0,
/// then the object must be a human.
/// </summary>
private const int CorrectExpectedResultForHuman = 0;
/// <summary>
/// Actually there is no strict rule about the value of learning rate. It is a tuning parameter
/// that will depend on the context(problem domain), which means, we will continue to experiment
/// and find out which learning rate works best for optimizing the weights for the specific problem.
/// The value of learning rate should be between 0 and 1.Usually it should be a very small number,
/// something like 0.1.
/// </summary>
private const double LearningRate = 0.1;
/// <summary>
/// Weight for WidthHeightRatio
/// </summary>
public double Weight1 { get; private set; }
/// <summary>
/// Weight for ReflectedLightPercentage
/// </summary>
public double Weight2 { get; private set; }
/// <summary>
/// Strategy
/// ============
/// Y = Σ (W * X) + b
/// Detection Result = f(Y) = Activation Function
///
/// Here, we are using the Neural Network for Binary Classification. That means, The Activation function will result
/// a binary number 0 or 1. If result is 1, then we consider the object as a Car. If the result is 0, we consider the
/// object as a human.
///
/// For simplicity, we assume that, b or bias = 0.
///
/// Now, we will present our training data and calculate the Result for each set of data.
/// For each epoch we will calculate Result = f(Y), where Y = Σ (W * X) + b.
/// When presenting vehicle training Data, we expect the Result = f(Y) to be 0. So, 0 is the correct output
/// and 1 is the error output. When presenting human training data, we expect the Result = f(Y) to be 1. So, 1 is the
/// correct output and 0 is the error output.
/// </summary>
private int DetectionFunction(double widthHeightRatio, double reflectedLightPercentage)
{
double weightedSum = Weight1 * widthHeightRatio + Weight2 * reflectedLightPercentage;
weightedSum = Math.Round(weightedSum, 2);
int detectionResult = ActivationFunction(weightedSum);
return detectionResult;
}
private int ActivationFunction(double weightedSum)
{
/*
This threshold value is NOT a magic number, rather it is an experimental value based on the data
set and the problem domain. For our problem domain, we find that, 0.5 can be a proper value that
can be used to do the classification.
*/
const double threshold = 0.50;
if (weightedSum > threshold)
{
return 1;
}
else
{
return 0;
}
}
private void TrainWithData(List<TrainingData> trainingData, int correctExpectedResult)
{
for (int i = 0; i < trainingData.Count; i++)
{
int detectionResult = DetectionFunction(trainingData[i].WidthHeightRatio, trainingData[i].ReflectedLightPercentage);
if (detectionResult == correctExpectedResult)
{
// The result is correct, so we do not need to change the Weights.
}
else
{
int currentOutput = detectionResult;
int errorProduced = correctExpectedResult - currentOutput;
double changeInWeight1 = LearningRate * trainingData[i].WidthHeightRatio * errorProduced;
double newWeight1 = Weight1 + changeInWeight1;
Weight1 = newWeight1;
double changeInWeight2 = LearningRate * trainingData[i].ReflectedLightPercentage *
errorProduced;
double newWeight2 = Weight2 + changeInWeight2;
Weight2 = newWeight2;
}
}
}
public void Learn(List<TrainingData> humanTrainingDataList, List<TrainingData> vehicleTrainingDataList)
{
/* We have 2 weights variable in this network. One weight is for WidthHeightRatio (Weight1) and another
* Weight is for for ReflectedLightPercentage (Weight2)
*
* Before the training, we initialize the 2 Weigths with some random values.
* Over time, these weights will be changed based on training data. */
Random random = new Random();
Weight1 = random.NextDouble();
Weight2 = random.NextDouble();
Console.WriteLine("Learning started with vehicle data...");
TrainWithData(vehicleTrainingDataList, CorrectExpectedResultForVehicle);
Console.WriteLine("\nLearning successfully completed with vehicle Data.\n");
Console.WriteLine("Learning started with human data...");
TrainWithData(humanTrainingDataList, CorrectExpectedResultForHuman);
Console.WriteLine("\nLearning successfully completed with human Data.\n");
Console.WriteLine("Value of W1 = {0}", Weight1);
Console.WriteLine("Value of W2 = {0}\n", Weight2);
}
public void Detect()
{
try
{
Console.Write("\nEnter width to height ratio:");
double widthHeightRatio = Convert.ToDouble(Console.ReadLine());
Console.Write("Enter percentage of reflected light:");
double percentageOfReflectedLight = Convert.ToDouble(Console.ReadLine());
int detectionResult = DetectionFunction(widthHeightRatio, percentageOfReflectedLight);
string alertMessage;
switch (detectionResult)
{
case CorrectExpectedResultForVehicle:
{
alertMessage = "Vehicle Alert!";
}
break;
case CorrectExpectedResultForHuman:
{
alertMessage = "Pedestrian Alert!";
}
break;
default:
throw new Exception("Invalid Result");
}
Console.WriteLine(alertMessage);
}
catch (FormatException)
{
Console.WriteLine("\nSorry, You have not entered valid double number.");
}
}
}This is the class for Training Data
public class TrainingData
{
public TrainingData(double widthHeightRatio, double reflectedLightPercentage)
{
this.WidthHeightRatio = widthHeightRatio;
this.ReflectedLightPercentage = reflectedLightPercentage;
}
public double WidthHeightRatio { get; private set; }
public double ReflectedLightPercentage { get; private set; }
}Finally, this is how we can train the Network and start detecting a Vehicle and a Pedestrian.
public static class Program
{
static void Main()
{
List<TrainingData> carTrainingData = new List<TrainingData>
{
new TrainingData(widthHeightRatio : 1.1, reflectedLightPercentage : 0.6),
new TrainingData(widthHeightRatio : 1.2, reflectedLightPercentage : 0.7),
new TrainingData(widthHeightRatio : 1.3, reflectedLightPercentage : 0.75),
new TrainingData(widthHeightRatio : 1.4, reflectedLightPercentage : 0.8)
};
List<TrainingData> humanTrainingData = new List<TrainingData>
{
new TrainingData(widthHeightRatio : 0.1, reflectedLightPercentage : 0.1),
new TrainingData(widthHeightRatio : 0.2, reflectedLightPercentage : 0.15),
new TrainingData(widthHeightRatio : 0.3, reflectedLightPercentage : 0.15),
new TrainingData(widthHeightRatio : 0.4, reflectedLightPercentage : 0.2)
};
NeuralNetwork network = new NeuralNetwork();
network.Learn(humanTrainingData, carTrainingData);
network.Detect();
Console.ReadKey(true);
}
}